
Think about how people ask about sunglasses.
In the old search model, someone queries “best smart sunglasses” and scans the links in a SERP.
In the new model, they ask, “What’s the deal with Meta Ray-Bans?” and get a synthesized answer with specs, use cases, and reviews – often without seeing a single webpage, including the SERP.
That shift defines the new frontier: your content doesn’t have to rank. It has to be retrieved, understood, and assembled into an answer.
The game used to be: write a page, wait for Google/Bing to crawl it, hope your keywords matched the query, and pray no one bought the ad slot above you. But that model is quietly collapsing.
Generative AI systems don’t need your page to appear in a list – they just need it to be structured, interpretable, and available when it’s time to answer.
This is the new search stack. Not built on links, pages, or rankings – but on vectors, embeddings, ranking fusion, and LLMs that reason instead of rank.
You don’t just optimize the page anymore. You optimize how your content is broken apart, semantically scored, and stitched back together.
And once you understand how that pipeline generally works, the old SEO playbook starts to look quaint. (These are simplified pipelines.)

Meet the new search stack
Under the hood of every modern retrieval-augmented AI system is a stack that’s invisible to users – and radically different from how we got here.
Embeddings
Each sentence, paragraph, or document gets converted into a vector – a high-dimensional snapshot of its meaning.
- This lets machines compare ideas by proximity, not just keywords, enabling them to find relevant content that never uses the exact search terms.
Vector databases (vector DBs)
These store and retrieve those embeddings at speed. Think Pinecone, Weaviate, Qdrant, FAISS.
- When a user asks a question, it’s embedded too – and the DB returns the closest matching chunks in milliseconds.
BM25
Old-school? Yes.
Still useful? Absolutely.
BM25 ranks content based on keyword frequency and rarity.
- It’s great for precision, especially when users search for niche terms or expect exact phrase matches.
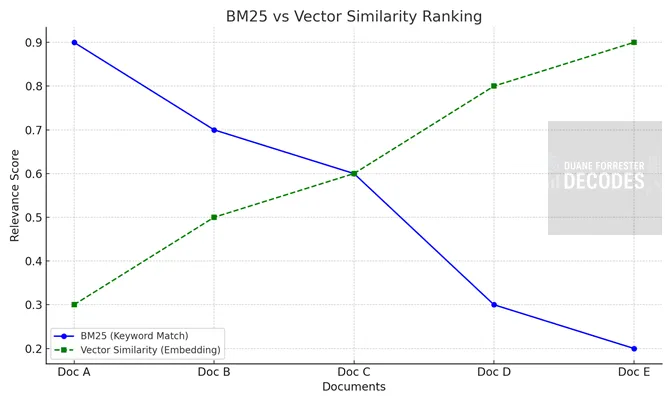
This graph is a conceptual comparison of BM25 vs vector similarity ranking behavior. Based on hypothetical data to illustrate how the two systems evaluate relevance differently – one prioritizing exact keyword overlap, the other surfacing semantically similar content. Note the documents appear in order.
RRF (Reciprocal Rank Fusion)
This blends the results of multiple retrieval methods (like BM25 and vector similarity) into one ranked list.
- It balances keyword hits with semantic matches so no one approach overpowers the final answer.
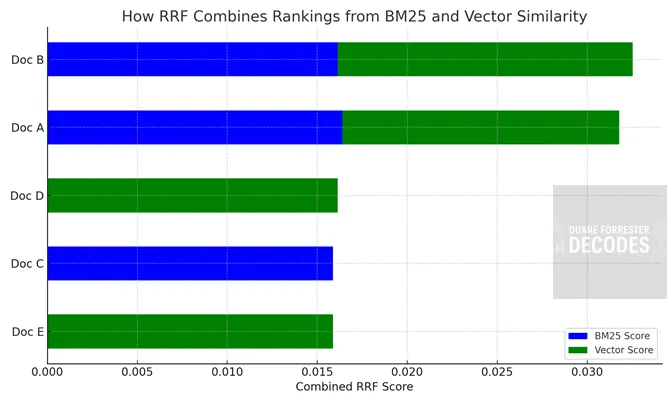
RRF combines ranking signals from BM25 and vector similarity using reciprocal rank scores. Each bar below shows how a document’s position in different systems contributes to its final RRF score – favoring content that ranks consistently well across multiple methods, even if it’s not first in either. We can see the document order is refined in this modeling.
LLMs (Large Language Models)
Once top results are retrieved, the LLM generates a response – summarized, reworded, or directly quoted.
- This is the “reasoning” layer. It doesn’t care where the content came from—it cares whether it helps answer the question.
And yes, indexing still exists. It just looks different.
There’s no crawling and waiting for a page to rank. Content is embedded into a vector DB and made retrievable based on meaning, not metadata.
- For internal data, this is instant.
- For public web content, crawlers like GPTBot and Google-Extended still visit pages, but they’re indexing semantic meaning, not building for SERPs.
Why this stack wins (for the right jobs)
This new model doesn’t kill traditional search. But it leapfrogs it – especially for tasks traditional search engines never handled well.
- Searching your internal docs? This wins.
- Summarizing legal transcripts? No contest.
- Finding relevant excerpts across 10 PDFs? Game over.
Here’s what it excels at:
- Latency: Vector DBs retrieve in milliseconds. No crawl. No delay.
- Precision: Embeddings match meaning, not just keywords.
- Control: You define the corpus – no random pages, no SEO spam.
- Brand safety: No ads. No competitors hijacking your results.
This is why enterprise search, customer support, and internal knowledge systems are jumping in head-first. And now, we’re seeing general search heading this way at scale.
How Knowledge Graphs enhance the stack
Vectors are powerful, but fuzzy. They get close on meaning but miss the “who, what, when” relationships humans take for granted.
That’s where knowledge graphs come in.
They define relationships between entities (like a person, product, or brand) so the system can disambiguate and reason. Are we talking about Apple the company or the fruit? Is “it” referring to the object or the customer?
Used together:
- The vector DB finds relevant content.
- The knowledge graph clarifies connections.
- The LLM explains it all in natural language.
You don’t have to pick either a knowledge graph or the new search stack. The best generative AI systems use both, together.
Tactical field guide: Optimizing for AI-powered retrieval
First, let’s hit a quick refresh on what we’re all used to – what it takes to rank for traditional search.
One key thing here – this isn’t exhaustive, this overview. It’s simply here to set the contrast for what follows. Even traditional search is hella complex (I should know, having worked inside the Bing search engine), but it seems pretty tame when you see what’s coming next!
To rank in traditional search, you’re typically focused on things like this:
- You need crawlable pages, keyword-aligned content, optimized title tags, fast load speeds, backlinks from reputable sources, structured data, and solid internal linking.
- Sprinkle in E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness), mobile-friendliness, and user engagement signals, and you’re in the game.
It’s a mix of technical hygiene, content relevance, and reputation – and still measured partly by how other sites point to you.
Now for the part that matters to you: How do you actually show up in this new generative-AI powered stack?
Below are real, tactical moves every content owner should make if they want generative AI systems like ChatGPT, Gemini, CoPilot, Claude, and Perplexity to pull from their site.
1. Structure for chunking and semantic retrieval
Break your content into retrievable blocks.
Use semantic HTML (<h2>, <section>, etc.) to clearly define sections and isolate ideas.
Add FAQs and modular formatting.
This is the layout layer – what LLMs first see when breaking your content into chunks.
2. Prioritize clarity over cleverness
Write like you want to be understood, not admired.
Avoid jargon, metaphors, and fluffy intros.
Favor specific, direct, plain-spoken answers that align with how users phrase questions.
This improves semantic match quality during retrieval.
3. Make your site AI-crawlable
If GPTBot, Google-Extended, or CCBot can’t access your site, you don’t exist.
Avoid JavaScript-rendered content, make sure critical information is visible in raw HTML, and implement schema.org tags (FAQPage, Article, HowTo) to guide crawlers and clarify content type.
4. Establish trust and authority signals
LLMs bias toward reliable sources.
That means bylines, publication dates, contact pages, outbound citations, and structured author bios.
Pages with these markers are far more likely to be surfaced in generative AI responses.
5. Build internal relationships like a Knowledge Graph
Link related pages and define relationships across your site.
Use hub-and-spoke models, glossaries, and contextual links to reinforce how concepts connect.
This builds a graph-like structure that improves semantic coherence and site-wide retrievability.
6. Cover topics deeply and modularly
Answer every angle, not just the main question.
Break content into “what,” “why,” “how,” “vs.,” and “when” formats.
Add TL;DRs, summaries, checklists, and tables.
This makes your content more versatile for summarization and synthesis.
7. Optimize for retrieval confidence
LLMs weigh how confident they are in what you’ve said before using it.
Use clear, declarative language.
Avoid hedging phrases like “might,” “possibly,” or “some believe,” unless absolutely needed.
The more confident your content sounds, the more likely it is to be surfaced.
8. Add redundancy through rephrasings
Say the same thing more than once, in different ways.
Use phrasing diversity to expand your surface area across different user queries.
Retrieval engines match on meaning, but multiple wordings increase your vector footprint and recall coverage.
9. Create embedding-friendly paragraphs
Write clean, focused paragraphs that map to single ideas.
Each paragraph should be self-contained, avoid multiple topics, and use a straightforward sentence structure.
This makes your content easier to embed, retrieve, and synthesize accurately.
10. Include latent entity context
Spell out important entities – even when they seem obvious.
Don’t just say “the latest model.” Say “OpenAI’s GPT-4 model.”
The clearer your entity references, the better your content performs in systems using knowledge graph overlays or disambiguation tools.
11. Use contextual anchors near key points
Support your main ideas directly – not three paragraphs away.
When making a claim, put examples, stats, or analogies nearby.
This improves chunk-level coherence and makes it easier for LLMs to reason over your content with confidence.
12. Publish structured extracts for generative AI crawlers
Give crawlers something clean to copy.
Use bullet points, answer summaries, or short “Key Takeaway” sections to surface high-value information.
This increases your odds of being used in snippet-based generative AI tools like Perplexity or You.com.
13. Feed the vector space with peripheral content
Build a dense neighborhood of related ideas.
Publish supporting content like glossaries, definitions, comparison pages, and case studies. Link them together.
A tightly clustered topic map improves vector recall and boosts your pillar content’s visibility.
Bonus: Check for inclusion
Want to know if it’s working? Ask Perplexity or ChatGPT with browsing to answer a question your content should cover.
If it doesn’t show up, you’ve got work to do. Structure better. Clarify more. Then ask again.
Final thought: Your content is infrastructure now
Your website isn’t the destination anymore. It’s the raw material.
In a generative AI world, the best you can hope for is to be used – cited, quoted, or synthesized into an answer someone hears, reads, or acts on.
This is going to be increasingly important as new consumer access points become more common – think of things like the next-gen Meta Ray Ban glasses, both as a topic that gets searched, and as an example of where search will happen soon.
Pages still matter. But increasingly, they’re just scaffolding.
If you want to win, stop obsessing over rankings. Start thinking like a source. It’s no longer about visits, it’s about being included.
This article was originally published on Duane Forrester Decodes on substack (as Search Without a Webpage) and is republished with permission.